Je vous propose aujourd'hui de découvrir ensemble la Stack Elastic. Le principe de cette série d'outils est de créer de manière automatique des dashboards à partir de données provenant des logs de vos serveurs. Cette stack, anciennement appelée ELK, est composée de 3 outils principaux :
- ElasticSearch est un moteur de recherche et d'analyse restful distribué
- Logstash est un "pipeline" kylie et qui traite en simultané des données provenant de multiples sources et qui les transforme ensuite vers n'importe quel système de stockage.
- Kibana permet de consulter des données provenant des ElasticSearch et de les explorer grâce à un dashboard entièrement personnalisable.
Récemment, un nouvel outil a été rajouté à la Stack Elastic : Beats. Nous ne traiterons pas ici de cet outil car il n'a d'intérêt que si vous utilisez plusieurs machines (c'est un agent léger qui permet aux machines de transmettre les données provenant de vos logs vers Logstash ou Elasticsearch)
Nous allons donc voir ensemble comment installer et configurer ces 3 outils. Notre objectif est de traiter les logs provenant de nginx pour créer un dashboard simplifiant l'accès aux données qui nous intérèssent.
Pour la suite de cet article j'utiliserais Ubuntu Xenial (16.04). Si vous souhaitez utiliser la même configuration que moi, voici ma configuration vagrant :
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/xenial64"
config.vm.network "private_network", ip: "192.168.50.50"
config.vm.provider "virtualbox" do |v|
v.memory = 4096
v.cpus = 2
end
endAvant de commencer
Avant de commencer il faut commencer par installer la version 8 ou supérieur de Java. Vous pouvez utiliser la distribution officielle d'Oracle ou utiliser la version open source OpenJDK
sudo apt-get update
sudo apt-get install openjdk-8-jdkElasticsearch
Nous allons commencer par l'installation d'ElasticSearch. Il existe différentes méthodes pour l'installer mais nous allons utiliser la méthode la plus simple, celle basée sur l'utilisation des Dépôts. On commence par importer la clé GPG d'ElasticSearch.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -On installe ensuite le paquet apt-transport-https afin de pouvoir utiliser les lignes deb https://domain distro main dans la liste des dépôts.
sudo apt-get install apt-transport-https Et ensuite il ne nous resque plus qu'à lancer l'installation.
sudo apt-get update
sudo apt-get install elasticsearchContrairement à d'autres applications, ElasticSearch n'est pas démarrée automatiquement à la fin de l'installation et n'est pas non plus rajoutée dans la liste des applications lancées au démarrage.
Pour indiquer à notre système de démarrer ElasticSearch au boot (Attention, j'utilise ici Ubuntu 16.04 qui utilise systemd au lieu de init donc vous devrez peut être adapter cette commande à votre système)
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service Avant de démarrer ElasticSearch, nous allons nous assurer que le serveur n'écoute que sur localhost afin d'éviter que n'importe qui puisse accéder à nos données depuis l'extérieur. Pour cela, nous allons éditer le fichier /etc/elasticsearch/elasticsearch.yml (dans tous les cas vous devriez avoir un pare feu pour éviter ce genre de problèmes).
network.host: localhost Autre petit détail, si vous êtes sur un système plutôt modeste, vous pouvez changer la quantité de RAM qui est alloué par Java en modifiant le fichier /etc/elasticsearch/jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m
-Xmx512mUne fois ces modifications effectuées, nous pouvons enfin démarrer ElasticSearch.
sudo systemctl start elasticsearch.servicePour s'assurer que l'installation s'est correctement effectuée et que le service fonctionne correctement on peut appeller l'URL http://localhost:9200
curl "localhost:9200"
{
"name" : "ddI1Qyn",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "t_0C9EZAR6alCe5k1rxfvg",
"version" : {
"number" : "6.1.2",
"build_hash" : "5b1fea5",
"build_date" : "2018-01-10T02:35:59.208Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}Si jamais le service ne démarre pas correctement, vous pouvez vérifier les journaux
sudo journalctl -n 50 -f -u elasticsearchEt le reste des erreurs peuvent être obtenu en lisant les logs à l'emplacement habituel /var/log/elasticsearch
Logstash
Maintenant que nous avons installé ElasticSearch, il va falloir remplir notre base de données avec les informations provenant de nos logs. Nous allons donc commencer par installer logstash.
sudo apt-get install logstashPuis nous allons enregistrer le service au démarrage
sudo systemctl daemon-reload
sudo systemctl enable logstash.serviceEnsuite, il va falloir créer un fichier de configuration pour expliquer à Logstash comment traiter nos données. La configuration fonctionne en 3 parties :
- La partie input, permet d'indiquer comment les données vont entrer dans le pipeline
- La partie filter va permettre d'indiquer comment parser et extraire les données
- La partie output permet d'indiquer où vont être envoyées les données
Dans notre cas, on souhaite utiliser les logs provenant de nginx donc nous allons utiliser l'input File.
Pour la partie filtre, les logs de nginx ont l'avantage d'avoir un format conventionnel et nous allons donc pouvoir utiliser un pattern grok pour extraire les informations (si vous voulez en apprendre plus sur l'ensemble des filtres qui sont disponibles au niveau de Logstash, n'hésitez pas à faire un tour sur la documentation). Enfin, pour la sortie nous allons envoyer nos données vers ElasticSearch.
# /etc/logstash/conf.d/01-local-dev.conf
input {
file { path => "/home/vagrant/access_log" }
}
filter {
grok {
match => { "message" => ["%{IPORHOST:[nginx][access][remote_ip]} - %{DATA:[nginx][access][user_name]} \[%{HTTPDATE:[nginx][access][time]}\] \"%{WORD:[nginx][access][method]} %{DATA:[nginx][access][url]} HTTP/%{NUMBER:[nginx][access][http_version]}\" %{NUMBER:[nginx][access][response_code]} %{NUMBER:[nginx][access][body_sent][bytes]} \"%{DATA:[nginx][access][referrer]}\" \"%{DATA:[nginx][access][agent]}\" %{NUMBER:[nginx][access][response_time]:float}"] }
remove_field => "message"
}
mutate {
add_field => { "read_timestamp" => "%{@timestamp}" }
}
date {
match => [ "[nginx][access][time]", "dd/MMM/YYYY:H:m:s Z" ]
remove_field => "[nginx][access][time]"
}
useragent {
source => "[nginx][access][agent]"
target => "[nginx][access][user_agent]"
remove_field => "[nginx][access][agent]"
}
geoip {
source => "[nginx][access][remote_ip]"
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "logstash-local-dev-%{+YYYY.MM.dd}"
}
}Une fois que vous êtes satisfait de votre configuration, vous pouvez démarrer le service Logstash
sudo systemctl start logstash.serviceSi vous souhaitez déboguer votre configuration, il est possible d'utiliser le module de sortie stdout {} de tester la configuration avec la commande :
sudo /usr/share/logstash/bin/logstash --debug --path.settings /etc/logstash -f /etc/logstash/conf.d/01-local-dev.confA partir de maintenant notre base de données ElasticSearch devrait se remplir en même temps que nos logs d'accès nginx. Pour vérifier que l'index est correctement créé, vous pouvez appeler l'API REST fournie par ElasticSearch :
curl "localhost:9200/_cat/indices?v" Kibana
Enfin nous allons pouvoir terminer avec la mise en place du dashboard Kibana. Comme d'habitude nous allons passer par les dépôts pour l'installer.
sudo apt-get install kibanaNous allons ensuite éditer la configuration /etc/kibana/kibana.yml afin de ne pas écouter les connexions venant de l'extérieur.
network.host: localhost Et une fois cette modification effectuée nous allons démarrer le service et l'enregistrer au démarrage.
sudo systemctl daemon-reload
sudo systemctl enable kibana.service
sudo systemctl start kibana.serviceSi vous voulez vérifier que kibana et correctement démarré, il vous suffit d'appeler l'URL racine de l'application
curl "localhost:5601"
<script>var hashRoute = '/app/kibana';
var defaultRoute = '/app/kibana';
var hash = window.location.hash;
if (hash.length) {
window.location = hashRoute + hash;
} else {
window.location = defaultRoute;
}</script>Avec notre configuration actuelle, il n'est pas possible d'accéder à kibana depuis l'extérieur. Nous allons donc utiliser nginx et créer un proxy pour accéder à notre dashboard et en profiter pour ajouter le système d'authentification basique. Pour générer le fichier qui contiendra les informations d'authentification nous allons utiliser le paquet apache2-utils
sudo apt-get install apache2-utils
sudo htpasswd -c /etc/nginx/htpasswd.users tutoUne fois ce fichier créé, nous pouvons configurer notre hôte virtuel sur nginx.
server {
listen 80;
server_name stats.local.development;
auth_basic "Acces interdit";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
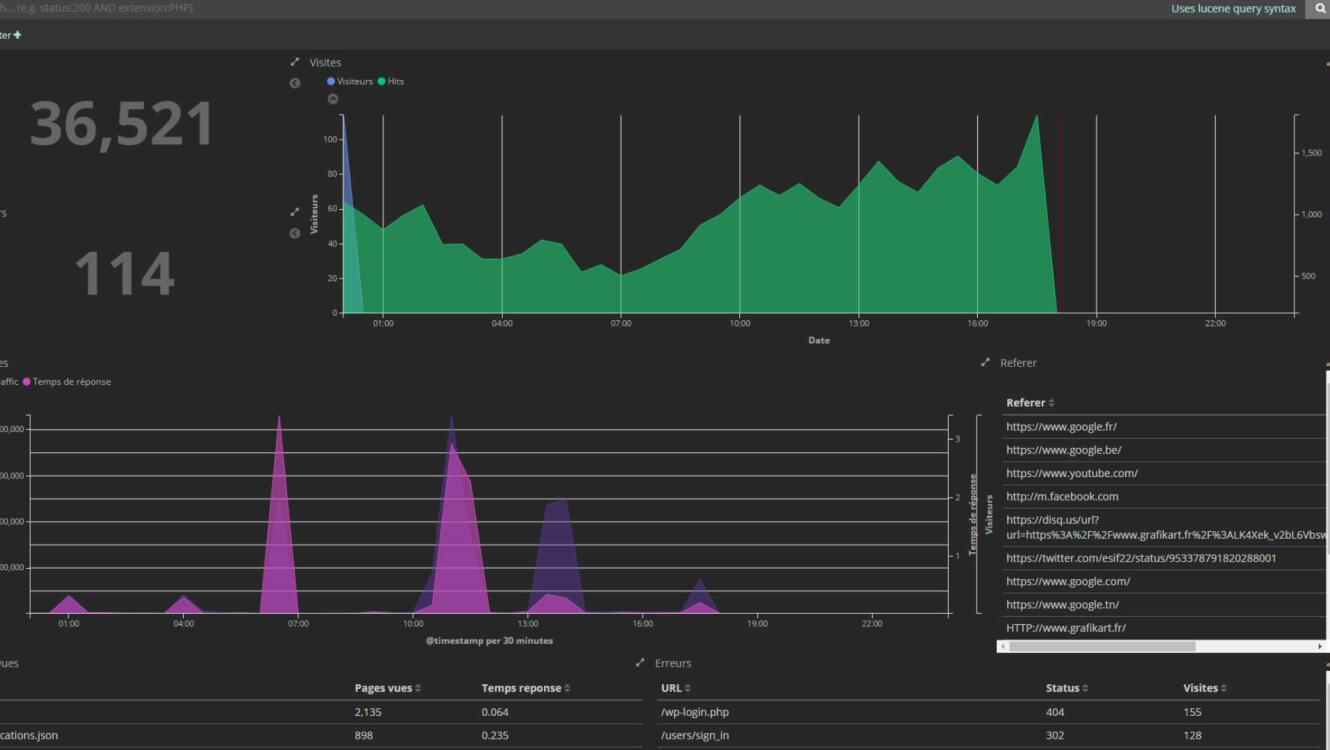
}Après avoir recharger nginx, vous devriez être en mesure d'accéder à votre dashboard Kibana avec l'URL que vous avez définie. A partir de là, il ne vous reste plus qu'à construire le dashboard en fonction de vos besoins et des informations que vous jugez pertinentes :
- On commence par définir un motif permettant de sélectionner les index à utiliser pour remplir les graphiques
- Ensuite, on crée les visualisations (graphiques, tableaux, cartes...) en sélectionnant le type de représentation puis les données à utiliser.
- Enfin, on crée un dashboard en sélectionnant les visualisations à utiliser et comment elles seront placées.
Et maintenant ?
Maintenant vous savez utiliser la Stack Elastic et vous pouvez et à d'autres cas d'utilisation. À vous de voir le type de données qui vous intéresse et ce que vous voulez en faire.
Une autre piste à explorer est l'utilisation du plugin X-pack qui permet de rajouter toute une série de fonctionnalités au système que l'on a déjà mis en place comme par exemple la création d'un système d'alerte, l'amélioration de la sécurité avec plusieurs niveaux de permission, la création de rapports personnalisés, etc...


